リポジトリのメソッド自動生成について
6.8 リポジトリのメソッド自動生成について
CRUDの基本的な処理を確認しましたが、ポイントはデータの更新や削除よりも、「リポジトリのfindByIsbn実装」にあるかも知れません。リポジトリによるメソッドの自動生成のおかげで、エンティティ取得がぐっと簡単になったのですから。
リポジトリを使えば、データベースを利用するためのメソッドを自分で作らなくとも非常に簡単にデータベースアクセスの処理を実装できることがよくわかるでしょう。しかし、結局、findByIsbnというメソッドはどこで実装されているのか?と不思議に思っている人も多いことでしょう。
インターフェースに宣言を用意しただけで、ここまで全くその実装がされていません。それなのに動いてしまうのです。不思議かもしれませんが、「メソッド名を元に、そのメソッドの処理を自動生成する」というのがJpaRepositoryの機能なのです。
あえて「どこで?」というなら、アプリケーション実行時に、定義されたリポジトリのインターフェースを元に内部的に実装クラスが生成されている(ただし利用する側からは存在が見えない)ということになります。この自動生成機能こそが、JpaRepositoryの魅力だ、といってよいでしょう。
6.8.1 自動生成可能なメソッド名
なぜ、このようなことが可能なのか。それはJpaRepositoryに「辞書によるコードの自動生成機能」が組み込まれているからです。
これは、データベースアクセスを行うメソッドでよく用いられる単語を辞書に持ち、それぞれの単語がどのような処理を行うのに用いられるかを推測してメソッドを自動生成する機能です。
例えば、「findByIsbn」というメソッドは、誰でも「isbnというプロパティが指定の値のものを検索するのだろう」とはだいたいわかります。findはエンティティを検索するメソッドで用いるものですし、byIsbnは「isbnというカラムから検索をする」ということが推測できます。すなわち、
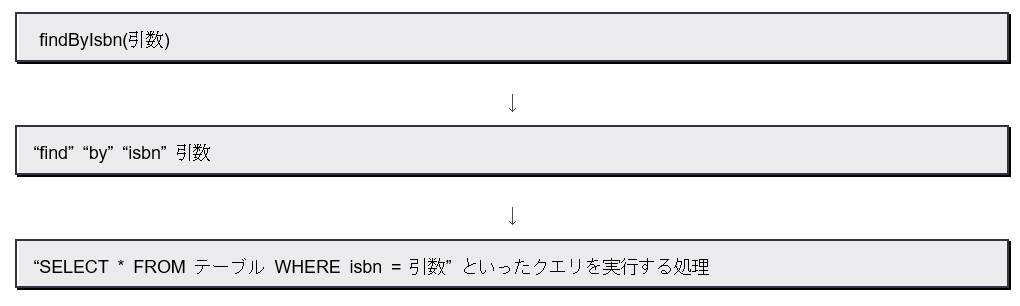
このようにメソッド名から処理を推測することは、かなり機械的に可能です。データベースにアクセスする基本的な処理は、誰が作成してもほとんど同じです。ならば、人間が毎回似たようなコードを書くよりも、プログラムにデータベースアクセスの処理そのものを自動生成させてしまったほうがいいだろう、と考えたのでしょう。
では、リポジトリのメソッド名では、どのような単語が理解できるのでしょうか。メソッド名として利用し、解析できる主な単語を簡単にまとめておきましょう。なお、それぞれの単語で生成されるクエリについても掲載しておきます。
6.8.2 And
2つの項目の値の両方に合致する要素を検索するような場合に用いられます。これを使って2つの項目名をつなぎ、それぞれの項目の値として引数を2つ用意すればいいでしょう。
■メソッド例

■生成されるクエリ
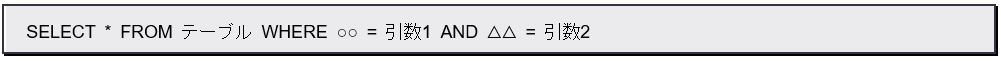
6.8.3 Or
2つの項目の値のどちらか一方に合致する要素を検索するような場合に用いられます。2つの項目名をつなぎ、それぞれの項目の値として引数を2つ用意します。
■メソッド例

■生成されるクエリ

6.8.4 Between
2つの引数で値を渡し、両者の間の値を検索するようなときに用いることができます。これにより指定の項目が一定範囲内の要素を検索します。
■メソッド例

■生成されるクエリ
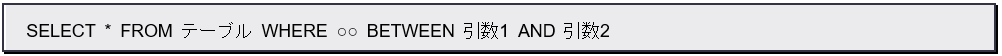
6.8.5 LessThan
数値の項目で、引数に指定した値より小さいものを検索します。
■メソッド例

■生成されるクエリ

6.8.6 GreaterThan
数値の項目で、引数に指定した値より大きいものを検索します。
■メソッド例

■生成されるクエリ

6.8.7 IsNull
指定の項目の値がnullのものを検索します。
■メソッド例

■生成されるクエリ

6.8.8 IsNotNull、NotNull
指定の項目の値がnullでないものを検索します。NotNullでもいいですし、IsNotNullでも理解します。
■メソッド例

■生成されるクエリ

6.8.9 Like
テキストのあいまい(LIKE)検索用です。指定の項目から値をあいまい検索します。ただしワイルドカードの設定までは自動でやってくれないので、引数に渡す値に随時ワイルドカードを付ける必要があるでしょう。
■メソッド例

■生成されるクエリ

6.8.10 NotLike
あいまい検索で検索文字列を含まないものを検索します。やはりワイルドカードは引数に明示的に用意します。
■メソッド例

■生成されるクエリ

6.8.11 OrderBy
並び順を指定します。通常の検索メソッド名の後に付けるとよいでしょう。また、項目名の後にAscやDescを付けることで、昇順か降順かを指定できます。
■メソッド例

■生成されるクエリ

6.8.12 Not
指定の項目が引数の値と等しくないものを検索します。
■メソッド例

■生成されるクエリ

6.8.13 メソッド生成を活用するためのポイント
実際にJpaRepositoryでメソッドを定義してみると、思ったように動いてくれないかも知れません。もっとも多いのは「例外が発生して動かない」というものでしょう。メソッドをうまく解析できないとメソッドの実装が正常に行なわれず、リポジトリ自体が動かなくなります。そこでうまく動かないときのチェックポイントを整理しておきましょう。
■メソッド名はキャメルケースが基本
メソッド名は、検索条件に関する各要素の単語の最初の文字だけを大文字にしてひとつなぎにする、いわゆる「キャメルケース」で書きます。この「各単語の1文字目だけを大文字にする」という点を理解していないとエラーになります。例えば「findByName」という名前を「findbyName」とすると例外が発生し、メソッドは生成されないのです。
■メソッド名の単語の並びをチェック
メソッド名から自動的に生成されるとはいっても、実は単語の並び順などがシビアです。例えば、findByIdIsNotNullOrderByIdDescというメソッドは問題ありませんが、findOrderByIdDescByIdIsNotNullとしてしまうとアプリケーション実行時に例外が発生します。単語の並び順として、ざっと以下のようなルールを考えておくとよいでしょう。

「By○○」といった対象となる項目の指定は一番最初にし、OrderByなど取得したエンティティの並び替えなどは最後に付けるようにします。
このように、JpaRepositoryを利用したリポジトリの作成は、エンティティ検索を劇的に簡略化してくれます。せっかくSpring Frameworkを使うのですから、これを最大限活用しない手はないでしょう。
これ以上の複雑なクエリについては第8章で扱いますが、「単純な検索はすべて自動生成メソッドで。複雑な検索処理だけ、DAOを定義して利用する」というように、両者をうまく組み合わせていくのがよいでしょう。